
长期以来,对于拥有成千上万台服务器的互联网各大厂商而言,如何提升服务器资源利用率,降低IT基础设施的TCO(总拥有成本)成为数据中心集群建设的重要问题。Gartner调研数据显示全球数据中心服务器CPU利用率只有6%~12%。这是因为企业往往为在线业务预留大量的服务器资源以保证其服务质量。与此同时随着数据分析和人工智能训练的大规模应用,离线业务对计算资源的需求又在日益增长。基于此,在保障在线作业性能的前提下,将在线集群的空闲资源分配给离线作业成为提升数据中心整体资源利用率的理想方法。如今,在离线混部方案成为各大互联网公司提升服务器资源的有效集群方案。
在离线混部方案,即将在线业务与离线业务混合部署到统一的物理集群上,通过资源隔离、调度等控制手段,充分利用集群资源,在保证服务稳定的同时提升数据中心的资源利用率。以微博为例,基于Kubernetes和HadoopYARN构建的在离线混部方案,充分发挥英特尔至强可扩展处理器集成的英特尔®资源调配技术 (英特尔®RDT)和英特尔®Speed Select 技术(英特尔®SST),实现了大幅度提升CPU利用率的同时保证了大规模业务服务的落地。
在线业务和离线业务现状和挑战
微博将混部概念的应用类型分为在线业务和离线业务两种。在线和离线业务如何划分?微博认为在线业务特点包括但不限于:任务运行时间长,响应延时敏感高,对稳定向要求较高,对服务质量要求高,服务不稳定业务会立马感知并且带来损失,比如广告搜索业务、网页搜索、即时通信等;而离线业务的特点包括但不限于非延时敏感,可重试,运行时间较短在几十分钟左右,一般为大数据处理、分析、机器学习训练作业等服务。
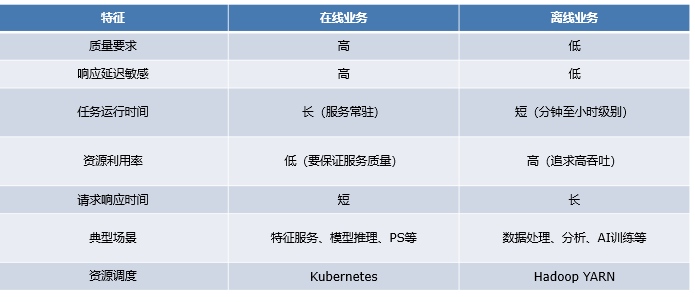
从微博业务的特征可以看到,在线业务资源平均利用率不高,离线业务资源不够用等特征,通过整合方案实现时间和资源上的互补,既要保证服务质量,又可以提高集群的资源的利用率,降低TCO。
如何通过填充离线作业把集群各个时段的在线空闲资源利用起来?微博结合实际业务通过通过在线业务容器化,并把部分离线作业部署在在线的统一资源池节点上,通过充分利用英特尔至强可扩展处理器为核心的服务器资源,达到了提升资源利用率的目的。
微博通过Hadoop作业通过YARN提交,k8s作业通过APIServer提交,实现业务方无感知的离线混部方案,通过ApplicationMaster管控Hadoop节点和混部节点中的离线任务,混部节点中部署的NodeManager以及Kubelet,分别用于离线服务和在线服务的管控。
保证在线业务的质量保证(QoS),防止受到离线作业干扰
在现实场景中,在线业务和离线业务诉求不同决定了资源需求和性能敏感度的异同。在线机房关注业务聚集的是用户体验、访问速度,而离线业务更关注的是计算、存储基础设施的规模。比如在线业务中的微博热点实时新闻的进程就需要优先推送,背后运行的一些进程不同,对CPU等关键资源的依赖性就有所不同。
如果在离线业务不做隔离,这样多种作业要竞争共享资源(如CPU、缓存、内存、内存带宽、网络带宽),比如在混合部署环境中,宿主机的资源(包括CPUcache和内存带宽)都是共享的。但是如果有一个消耗cache的应用快速消耗了L3缓存,或者一个应用消耗了系统大量内存带宽,就会因竞争L3缓存资源而引起的性能干扰,增加了在离线混部作业性能预测的难度。那么如何保证其他虚拟机应用呢?如何限制这些“可恶”的邻居呢?
针对上诉问题,以前都是通过控制虚拟机逻辑资源来实现,通过虚拟层对于混部作业调度和资源管理的颗粒度还是太粗,针对处理器缓存这样敏感而稀缺的资源,几乎是无能为力的。
对于微博而言,微博基于混部节点隔离技术来实现业务之间的防干扰。资源隔离技术分为操作系统层的资源隔离技术和硬件层的资源隔离技术。微博的混部系统实例就采用了软件资源隔方案,通过占用资源少、部署快的容器技术结合CPU内置的调配能力来实现资源的隔离、监控和管理。不仅通过多个进程并发的执行,来提高了CPU的利用率,还基于CPU更细粒度的资源调度和资源管理能力,来减少在离线作业的相互干扰下,保证更好的实现在线业务的质量同时,加速离线业务的运行。
打造硬件级别的抗干扰机制是提高资源利用率的核心能力
英特尔至强可扩展处理器作为最重要的计算资源,提供了硬件级别的细粒度抗干扰机制,实现了不同的资源调度机制使得作业在运行时具有不同的抗干扰性。比如英特尔®资源调配技术 (英特尔®RDT)和英特尔®Speed Select 技术(英特尔®SST),通过对CPU性能的细粒度控制和缓存调度功能来更好的实现分时共享或抢占式调度,从而提升了由隔离和控制缓存资源引起的性能干扰。
在动态环境中释放系统性能
英特尔®资源调配技术 (英特尔®RDT) 使得应用程序、虚拟机 (VM)和容器使用共享资源(例如最新级别高速缓存 (LLC)和内存带宽)的方式的可见性和可控性达到全新水平。它使工作负载整合密度、性能稳定性以及动态服务交付有了革命性飞跃,有助于提升整个数据中心的效率和灵活性,并全面降低总拥有成本(TCO)。随着软件定义的基础设施和先进的资源感知型编排技术不断推动行业变革,英特尔®RDT 成了优化应用程序性能的关键功能,并增强了使用英特尔®至强®处理器的服务器系统编排和虚拟化管理的功能。
英特尔®RDT 提供了一个由多个组件功能(包括 CMT、CAT、CDP、MBM和MBA)组成的框架,用于缓存和内存监控及分配功能。这些技术可以跟踪和控制平台上同时运行的多个应用程序、容器或VM 使用的共享资源,例如最后一级缓存(LLC) 和主内存(DRAM) 带宽。RDT可以帮助检测“吵闹的邻居”并减少性能干扰,从而确保复杂环境中关键工作负载的性能。
这5个功能模块分为监控和控制两大类,CMT和MBM为监控技术,而CAT、MBA和CDP为控制技术。具体而言:
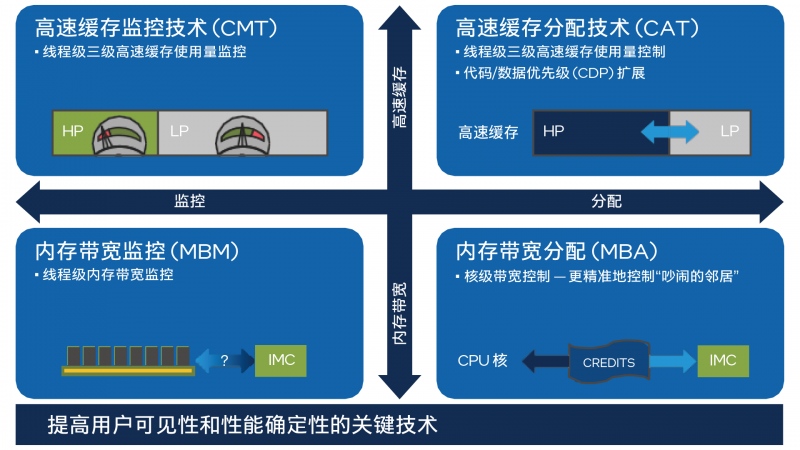
高速缓存监控技术 (CMT)
借助监控单个线程、应用程序或 VM对最后一级缓存 (LLC)的利用率所获得的新洞察,CMT改进了工作负载表征,实现了先进的资源感知型调度决策,能帮助检测“吵闹的邻居”,并改进性能调试。
内存带宽监控 (MBM)
内存带宽监控 (MBM)可以独立跟踪多台虚拟机或多个应用程序,同时对每个运行线程进行内存带宽监控。优点包括:对“吵闹的邻居”的检测,对带宽敏感型应用程序的性能界定和调试的检测,以及对更高效的非一致性内存访问(NUMA) 感知型调度的检测。
高速缓存分配技术 (CAT)
CAT支持软件引导的缓存容量重新分配,使重要的数据中心VM、容器或应用程序能够从提升缓存容量和减少缓存争用中受益。CAT可用于增强运行时确定性,并且在各种优先级工作负载的资源争用中优先考虑重要的应用程序,如虚拟交换机或数据平面开发套件(DPDK) 数据包处理应用程序。
代码和数据优先级 (CDP)
代码和数据优先级 (CDP)作为 CAT的专用扩展,实现了对最新级别 (L3)高速缓存中代码和数据放置的独立控制。某些特殊类型的工作负载可从增加的运行时决策中受益,从而提高应用程序性能的可预测性。
内存宽带分配 (MBA)
MBA可对工作负载可用的内存宽带进行近似和间接控制,从而为系统中存在的“吵闹的邻居”提供全新水平的干扰抑制和带宽整形。
欢迎进入细粒度控制时代
细粒度对于混部作业调度和资源管理具有重要意义,细粒度能够更好的规划不同作业阶段与阶段之间的有序混部运行,减少资源竞争,降低性能干扰,对于混部资源管理,基于细粒度可以设计更为精细的资源动态算法,合理利用作业运行期间的碎片资源,进一步提高资源利用率。英特尔®Speed Select 技术(英特尔®SST)包含的一组强大的全新功能,帮助CPU性能进行细粒度控制,从而优化总拥有成本。
如今,微博已完成在离线混部节点规模达到上千台,为离线任务提供数万个VCore的计算能力,通过在离线混部方案实现了极致的弹性调度,助力微博在热点事件/高峰的业务场景下,k8s节点弹性扩容离线集群的能力,在调度方面,通过更有计划的调度,实现了资源画的精细化,可以更精准的预测热点概率,优化调度能力,减少热点率。
在检测冲突和资源隔离方面,基于英特尔RDT、CPUQoS以及相关的隔离、调度等技术,实现了对缓存空间,内存带宽等细粒度的管理,实现了更好的检测冲突和资源隔离,并根据业务来分配真实的CPU资源的能力。不仅平均CPU利用率从25%以下,提升到60%以上,而且在线服务的指标影响范围可控下,离线任务也实现了更快的运行速度,从而支持更多的业务进入在离线混部场景。









